
Linguix Rewriter has become an essential tool for most of our users for many reasons. Here are just a few of them:
- You can deeply focus on your thoughts and the value you provide while writing. Without the rewriter, you’d be interrupted with your own thoughts about more suitable synonyms or ways to enhance your copy.
- You spend less time editing because the rewriter helps you make your sentences clear and nativelike as you type.
- AI and machine learning are now able to create amazing content that is indistinguishable from human one. There are even articles written by robots! The rewriter is no exception.
Technology doesn’t stand still and neither does Linguix. The updated rewriter has shown significant and measurable improvements. Let’s discuss how our team has achieved these results and define various metrics that have helped us to provide a more sophisticated experience in Linguix Rewriter 2.0.
Metrics to Determine the Quality of Linguix Rewriter
The Bleu Score. The Bilingual Evaluation Understudy score, or BLEU for short, is a metric for comparing a generated sentence to a reference sentence. This metric evaluates the quality of the machine learning translation.
In fact, the closer the value to 0, the better. It implies that the rewriter generates “smarter” results, and chooses synonyms that retain initial meaning.
The Jaccard similarity coefficient is a measure used in understanding the similarities between sample sets. As with the BLEU score, the appropriate Jaccard Index value tends to 0. Again, the closer to 0, the better the results.
Language-Agnostic BERT Sentence Embedding (LaBSE) and Cosine similarity.
The LaBSE model encodes text into high dimensional vectors so that the text vectors close in meaning are geometrically close to each other (they’re placed into a shared multi-dimensional vector space).
Cosine similarity, in turn, helps to define how similar the pieces of text are. It measures the cosine of the angle between two vectors projected in this space. The closer the cosine value to 1, the smaller the angle and the greater the match between vectors.
Perplexity. Perplexity is a metric used to evaluate how good a language model is. The lower the perplexity score is, the better the language model works in terms of word prediction.
How We Conducted the Training
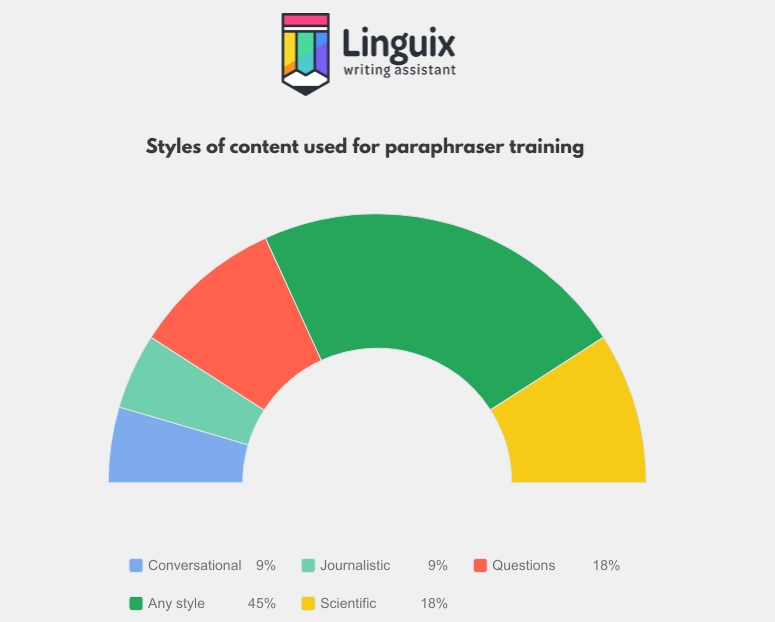
We took 11 datasets with 573,228,310 million sentences in various styles (from technical documentation to fiction) and trained our model. The goal was to make it able to handle texts of different types and styles. The one-to-one/one-to-many column represents whether the source sentence has one paraphrase option or several.
The Results
The quantitative analysis of our new model represents a higher quality of the paraphrasing generation compared to the previous model. The new model outperforms the old one in terms of text similarity:
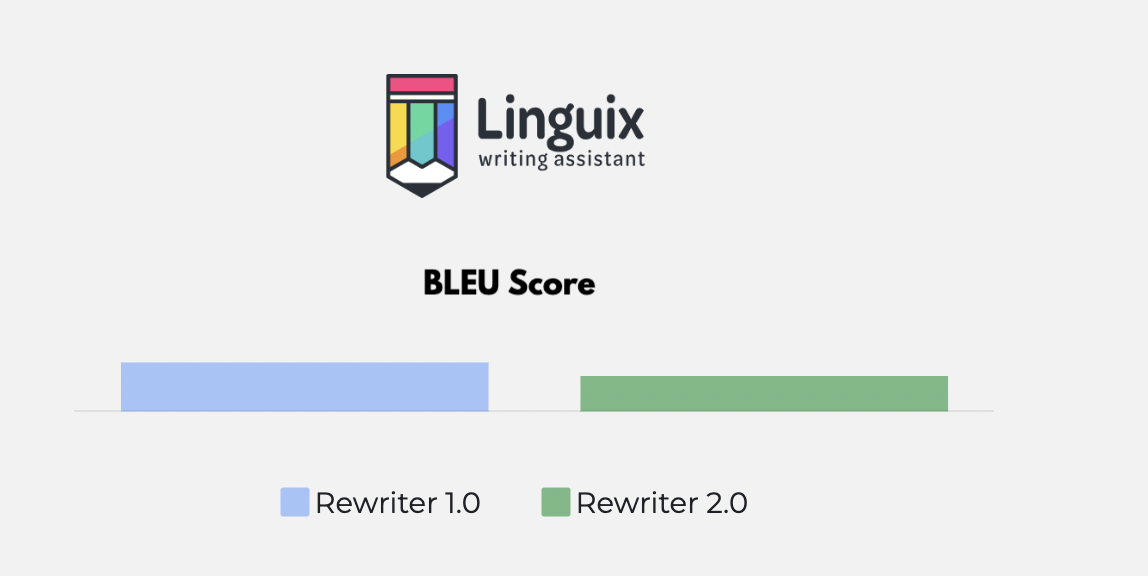
The BLEU score: 0.47↓ vs 0.65
The Jaccard similarity coefficient: 0.45↓ vs 0.51

Perplexity. Rewrites generated by Linguix rewriter 2.0 appeared to be more natural and native: 0.26↓ vs 4.99

The semantic similarity value of the new model is slightly lower than that of the previous model (0.80↓ vs 0.93), which is totally fine. The model generates a variety of options using other words but keeping the meaning of the source text as its target.

As such, for Linguix rewriter 2.0 we were able to improve the quality of the rephrased content while keeping the text meaning at the same level.
How to test the updated rewriter
You need to install Linguix browser extension or use Linguix web editor.


